

Incident Management Process Explained!
What is Incident Management Process?
Purpose & Scope
Purpose
The objective of Incident Management process is to restore normal service operation (as defined in the SLA with <Customer’s Name>) as quickly as possible, thus ensuring that the best possible levels of service quality and availability are maintained for <Customer’s Name>’s business.
Scope
All Incidents with a (possible) negative effect on the <Customer’s Name>’s service for which a SLA is signed, lies within the scope of Incident Management
The process will be applicable to all incidents or performance related requests by customer and internal automated alerts.
Definitions
Incident
Incident is an unplanned interruption to an IT service or reduction in the quality of an IT service or failure of a configuration item that has not yet impacted service.
Major Incident
The highest Category of Impact for an Incident. A Major Incident results in significant disruption to the <Customer Name>’s Business.
A definition of what constitutes a major incident must be agreed and documented.
Configuration Item
Configuration Item is any component that needs to be managed in order to deliver <Customer’s Name> IT Service.
Workaround
The workaround is an identified means of resolving a particular incident by allowing normal service to be resumed; however, it does not actually resolve the issue that caused the incident in the first place.
Service Request
It is a request from a User for information or advice, or for a Standard Change or for Access to <Customer’s Name> IT Service.
Supplier
A Third party responsible for supplying goods or Services that are required to deliver <Customer Name>’s IT Services.
Service Knowledge Management System (SKMS)
It is a set of tools and databases that are used to manage knowledge and information. The SKMS includes the Configuration Management System (CMS), Known Error Data Base (KEDB) as well as other tools and databases. The SKMS stores, manages, updates, and presents all information that an IT Service provider needs to manage the full Lifecycle of <Customer Name>’s IT Services.
Roles and Responsibilities
Incident Manager
Responsibilities
- Driving the efficiency & effectiveness of Incident Management Process.
- Producing management information.
- Managing the work of incident support staff.
- Monitoring the effectiveness of incident management process and make the recommendations for improvements.
- Managing Major Incidents.
- Develop & manage Incident management process and procedures.
Service Desk
Responsibilities
- Accept & register incidents
- Categorize & Prioritize Incidents
- Execute Initial diagnosis to restore the incident
- Refer incidents to the appropriate Support Group
- Tracks the progress incident during entire lifecycle (from start to end, register to close) to ensure that it is resolved within the agreed Service Level Agreement (SLA) and updates incident records if necessary
- Keeping users informed of progress
- Escalate to the appropriate management level when thresholds are violated
- Closing all resolved incidents, requests and other calls
- Conducting customer/user satisfaction call backs/surveys as agreed
- Report about Incidents
Application Management Team (2nd & 3rd Level Support)
Responsibilities
- Incident diagnosis and resolution.
- Identify the required changes to resolve an incident.
- Identify the requirement of partner involvement and initiate the process
Input, Output
Inputs
- Phone calls
- Emails
- Web Interface
- Event
- Input from Technical Staff
- Knowledge base, Known Error Database
Outputs
- Service Request
- Communications
- Notifications
- Solutions/Workarounds
Incident Management Process
Generic Incident Management Process
The ability to detect and resolve incidents, which results in lower downtime to the <Customer Name>’s business, which in turn means higher availability of the service.
This means that the business is able to exploit the functionality of the service as designed.
Check out the other related Incident Management Blogs
 |
 |
 |
 |
| Activity No. | Step | Description | Input/ Output | Role |
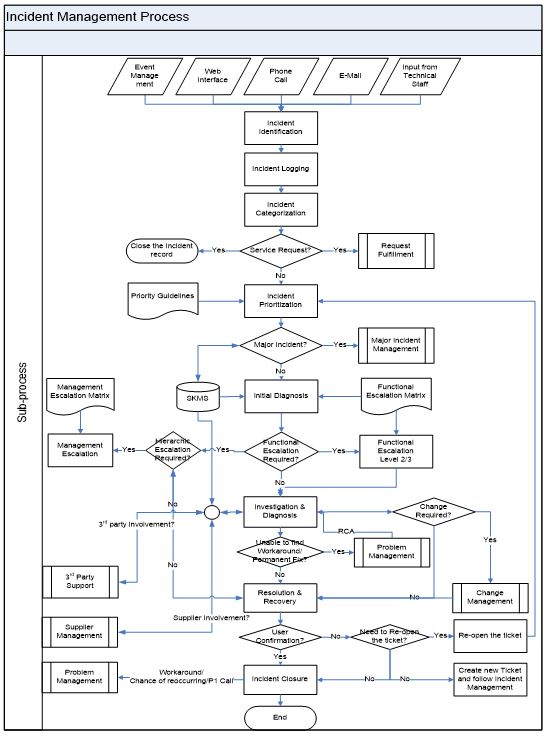
| 1 | Incident Identification | All key components should be monitored so that failures or potential failures are detected early so that the incident management process can be started quickly. Incident can be identified by Event management, web interface provided to user, User phone call, e-mail, Technical staff observation. | Input Event management Web interface E-mail Phone call Input from technical staff Output Incident | User |
| 2 | Incident Logging | All incidents must be fully logged and date/time stamped, regardless of whether they are raised through a Service Desk telephone call or whether automatically detected via an event alert. All relevant information relating to the nature of the incident must be logged so that a full historical record is maintained – and so that if the incident has to be referred to other support group(s), they will have all relevant information to hand to assist them. Minimum Information required when logging an incident can be found in <Incident Logging Checklist>. | Output Incident | Service desk |
| 3 | Incident Categorization | Allocate suitable incident categorization coding so that the exact type of the incident is recorded. | Input Incident Output Categorized incident | Service desk |
| 4 | Service Request? | Service Requests are sometimes incorrectly logged as incidents (e.g. a user incorrectly enters the request as an incident from the web interface). This check will detect any such requests and ensure that they are passed to the Request Fulfilment process. | Input Output | Service desk |
| 5 | Incident Prioritization | Allocate an appropriate prioritization code using <Priority Guidelines>. Prioritization can normally be determined by taking into account both the urgency of the incident (how quickly the business needs a resolution) and the level of impact it is causing. It should be noted that an incident’s priority may be dynamic – if circumstances change, or if an incident is not resolved within SLA target times, then the priority must be altered to reflect the new situation. | Input Incident Output Prioritization | Service desk |
| 6 | Major Incident Management? | A separate procedure, with shorter timescales and greater urgency, must be used for ‘major’ incidents. The process is discussed in detailed in Section 5.2. | Input Major Incident SKMS Output Closed Incident | Service desk |
| 7 | Initial Diagnosis | Service Desk Analyst must carry out initial diagnosis. Try to discover the full symptoms of the incident and to determine exactly what has gone wrong and how to correct it. It is at this stage that diagnostic scripts, knowledge base and known error information can be most valuable in allowing earlier and accurate diagnosis. | Input Incident SKMS Output Symptoms Resolution Steps | Service desk |
| 8 | Functional Escalation Level 2/3 | As soon as it becomes clear that the Service Desk is unable to resolve the incident itself (or when target times for first-point resolution have been exceeded – whichever comes first!) the incident must be immediately escalated for further support. | Input Incident<Functional Escalation Matrix> Output Functional Escalation | Service desk |
| 9 | Investigation & Diagnosis | Each of the support groups involved with the incident handling will investigate and diagnose what has gone wrong – and all such activities (including details of any actions taken to try to resolve or re-create the incident) should be fully documented in the incident record so that a complete historical record of all activities is maintained at all times. During this step, support group will identify the changes required in order to restore the service. If the change is required then a RFC should be raised with Change Management. And review the resolution after the change implementation. Support groups may also identify the involvement of suppliers or 3rd Party to restore the service. In that case Supplier Management process or 3rd Party communication should be invoked. | Input Incident SKMS Output RFC Partner involvement Resolution steps | 2nd/3rd Level Support |
| 10 | Unable to find Workaround/Permanent Fix? | If the Incident support groups (Level 1/2/3) unable to identify a workaround/permanent fix (With in the SLA time), then problem management should get involved in investigation & to find the root-cause. | Input Incident, SKMS Output Problem Record | Service desk |
| 11 | Resolution & Recovery | When a potential resolution has been identified, this should be applied and tested. Sufficient testing must be performed to ensure that recovery action is complete and that the service has been fully restored to the user(s). Regardless of the actions taken, or who does them, the Incident Record must be updated accordingly with all relevant information and details so that a full history is maintained. The resolving group should pass the incident back to the Service Desk for closure action. | Input Incident Resolution steps Output Incident restored | 2nd/3rd Level Support |
| 12 | Hierarchic Escalation | Hierarchic escalation is also used if the ‘Investigation and Diagnosis’ and ‘Resolution and Recovery’ steps are taking too long or proving too difficult. Hierarchic escalation should continue up the management chain so that senior managers are aware and can be prepared and take any necessary action, such as allocating additional resources or involving suppliers/maintainers. Hierarchic escalation is also used when there is contention about to whom the incident is allocated. | Input Incident<Management Escalation Matrix> Output Management Escalation | Service desk |
| 13 | User Confirmation? | After the incident resolution, it is required to confirm with the user to check the effectiveness of the resolution. If the incident is solved from the user prospective then we can proceed to close the incident. If the user not confirmed with in the agreed time lines then also we can proceed to close the incident. | Input Incident, Incident Resolution Output User confirmation | Service desk |
| 14 | Need to Re-open the ticket? | If the user not accepted the resolution (not solved the incident), then decision has to be taken to re-open the ticket. If the user comes back with the agreed timelines then we need to re-open the same incident (Rules to re-open should be agreed and documented). Otherwise we have to open a new Incident ticket and follow the process. | Input Incident Output Re-open Incident, New Incident | Service desk |
| 15 | Workaround/ Chance of reoccurring/ P1 Call | If the incident is resolved by providing a workaround (Not a permanent fix) or the support staff/service desk identify that the incident may reoccur again then, the update should be passed on to Problem management (To create a Problem ticket) for a permanent fix. If the Incident is a P1 Call, then it should be passed to Problem Management for Root cause Analysis (RCA )as a Proactive measure. | Input Incident Output Problem ticket | Service desk |
| 16 | Incident Closure | The Service Desk should check that the incident is fully resolved and that the users are satisfied and willing to agree the incident can be closed. The Service Desk should also execute the <Incident Closure Checklist> | Input Incident Output User satisfaction, Problem Ticket, Closed Incident | Service desk |
Another representation and interactions between other process is shown in the diagram below:
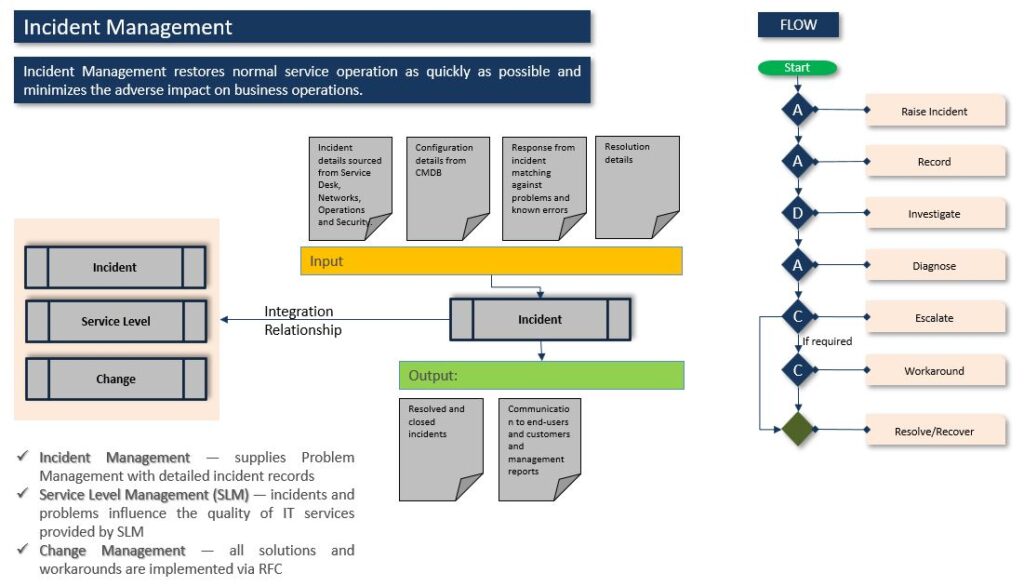
Major Incident Management Process
A separate procedure, with shorter timescales and greater urgency, must be used for ‘major’ incidents. A definition of what constitutes a major incident management must be agreed and ideally mapped on to the overall incident prioritization system – such that they will be dealt with through the major incident management process.
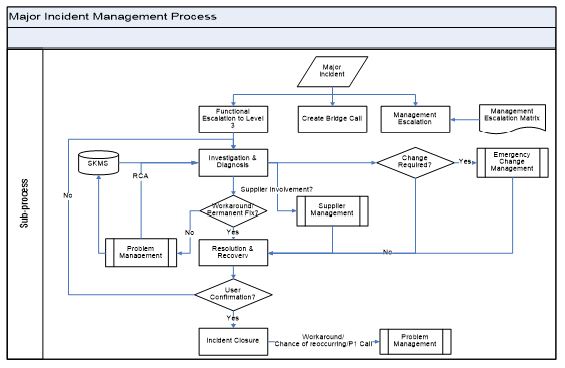
Note: Most of the activities are explained in the Incident management process. Only the activities which are not discussed earlier will be discussed here.
| Activity No. | Step | Description | Input/ Output | Role |
| 1 | Functional Escalation to Level 3 | As the business impact of the incident is high. Incident should be directly assigned to the 3rd Level for a quick resolution. | Input Incident Output Assignment | Service desk |
| 2 | Create Bridge Call | Taking the impact and urgency into the consideration, bridge call/Conference call should be initiated and all the stake holders should participate in the call. Problem management team should also get involved and try to find the underlying cause. | Input Incident Output Bridge Call | Incident Manager |
| 3 | Workaround/Permanent Fix? | During Investigation & diagnosis, if there is a work around or a permanent fix available, then the solution will be applied. If there is no work around or a permanent fix available then it should be referred to Problem management for Root Cause analysis (RCA). | Input Incident Output Problem ticket | Service desk |
Authored by Vijay Chander – All rights Reserved 2023


{kind=link}